업무나 데이터를 모아 전처리를 위해
작업하시는 분들이 많으실 텐데요.
웹에서 데이터를 받기위한 방법은 여러가지가 있습니다.
1. html 을 이용하는 방법
requests 모듈로 페이지 정보를 요청하고 뷰슙으로 html 구문분석을 통해
import requests
from bs4 import BeautifulSouptargetUrl = "타켓주소......"
source_code = requests.get(targetUrl, allow_redirects=False)
soup = Be autifulSoup(source_code.content, 'html.parser', from_encoding='utf-8')
list_data = soup.find_all('li')
for item in list_data:
print("item")
......
.....2. xhr 로그 기록으로 크롤링하기
requests 으로 페이지 정보 요청했는데 원하는 데이터가 없을때
Ajax 통해서 데이터를 주고 받는 경우라면 사용 가능한 방법입니다.
크롬 기준으로 F12(개발자모드) - 네트워크탭을 클릭 - XHR를 필터링하여 확인합니다
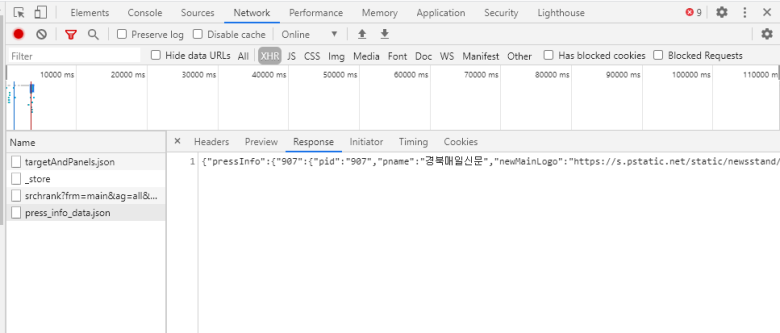
원하는데이터가 통신하는 부분을 찾아 response 부분을 확인하여 데이터를 확인합니다.
json 일수도 있고 html 일 수도 있습니다.
headers 를 클릭하여 post로 요청한는지 get으로 요청하는지 확인하여
post이면 해더정보를 보고 채워서 해더와 파라미터를 채워 보내줍니다.
headers ={
"Referer": "http://블라블라블라",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
}
params = {
"goodsCode": "1010101010",
"pageNo": "2",
"totalPage": "330"
}
res = requests.post("http://.....요청주소", headers=headers, data=params)
soup = BeautifulSoup(res.text, "html.parser")
get이면 headers 클릭후 Request URL에서 요청 주소만 찾아서 보내면 됩니다. 데이터를 가져오니까
그대로 데이터를 뷰슙이나 json형태로 처리하면 됩니다.
3. <script> </script> 안에 자바스크립트로 데이터가 들어 있을때
Ajax로 통신도 안하고 html 안에도 원하는 데이터가 안보이면 자바스크립트 부분을 확인합니다.
<script> 부분을 정규표현식으로 뽑아와 처리합니다.
그대로 데이터를 뷰슙이나 json형태로 처리하면 됩니다.
4. 셀레니움이나 playwright 같은 웹드라이버를 이용하여 크롤링 하기
위에 방식으로 처리가 안되는 홈페이지거나. 물리적인 버튼을 클릭해야 하거나 한다면 마지막으로
셀레니움을 이용하여 데이터를 뽑아옵니다.
보통은 Request 요청해보고 안되면 바로 웹드라이브 처리해서 크롤링을 하게 되는데
위에 쓴 순서대로 확인 해보면서 하시면 셀레니움 써서 리소스를 적게 소모하고도
크롤링을 할 수 있는 방법을 찾을수 있습니다.



댓글